
I read the book Monitoring with Graphite by Oreilly. Please read the book further. It is a good read. I’m just pending my own thoughts.
He mentioned something that is quite interesting that I have not really thought of. This can be divided into 3 main categories:
- Fault Detection
- Alerting
- Capacity Planning
Fault Detection
Fault Detection is to identify when a resource becomes unavailable or starts to perform poorly. Traditionally, system administrators employ thresholds to recognise the delta in a system’s behaviour
Alerting
Alerting constitutes the moment the monitoring system identifies a fault, the recipient(s) is alerted through som means perhaps like email, SMS so that further actions can be taken by the recipient(s)
Capacity Planning
The act of capacity planning is the ability to study trends in the data and use that knowledge make informed decisions about adding capacity now or in the near future. You can use Graphite to work on the time-series data
Pull and Push Model
Pull Model – The Traditional Approach to IT Monitoring centers around a polling agent spending resources to connect to remote users or appliances to determine their current status. However, traditional method of pull method have limitation in integrating trending and monitoring and often different software stacks is required.
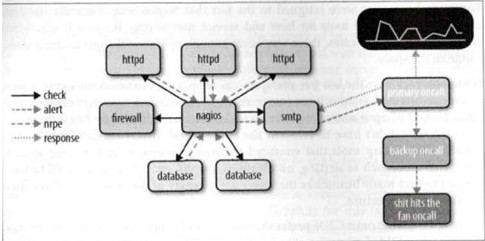
Push Model – Metrics are pushed from the sources to a unified storage repository, and providing with a consolidated set of data to drive both IT responses and business decisions. The advantage is that collection tasks are decentralised and we no longer require to scale our collection system horizontally as the architecture scale vertically. One of the interesting aspects of the push model is that we can isolate the functional responsibilities of the monitoring system.

Hi kittycool, this is great! I’ll have to read the book myself. Everything you’ve pulled out I can concur with. There’s never one perfect monitoring application either, many need other software in the stack to gain enough data for monitoring. Does the book also talk about AI influences on the field?
LikeLike