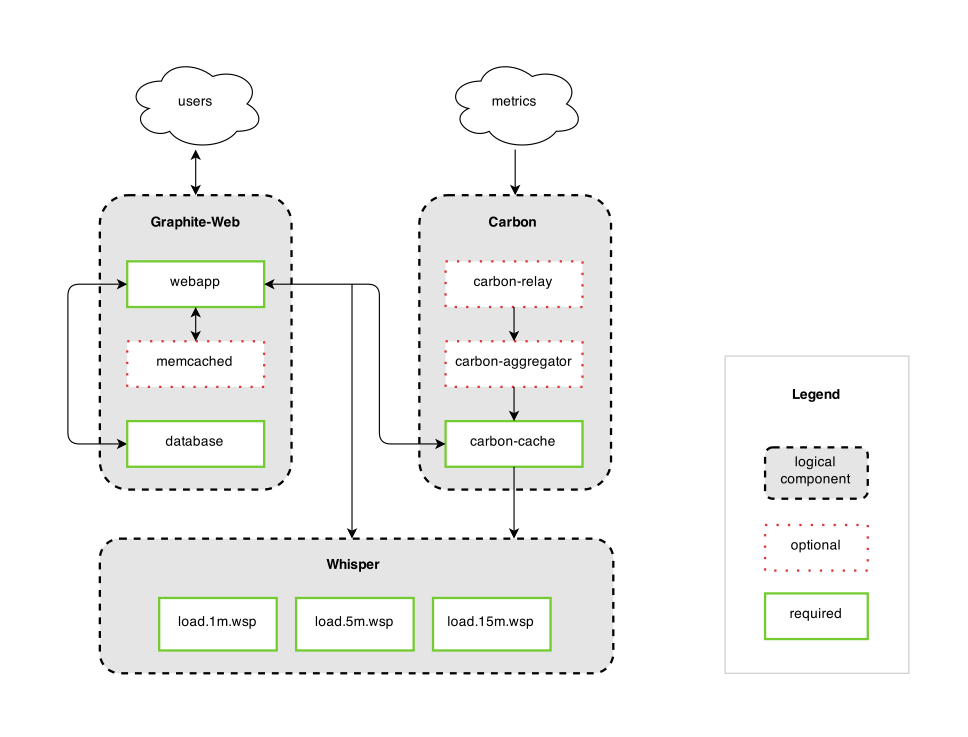
mpstat is a command-line utilities to report CPU related statistics.
For CentOS, to install mpstat, you have to install the sysstat package (http://sebastien.godard.pagesperso-orange.fr/)
# yum install sysstat
1. mpstat is very straigtforward. Use the command below. On my 32-core machine,
# mpstat -P ALL
11:10:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
11:10:13 PM all 40.75 0.00 0.03 0.00 0.00 0.00 0.00 59.22 1027.50
11:10:13 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1000.50
11:10:13 PM 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 2 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 4 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 5 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 7 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 16.50
11:10:13 PM 9 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 11 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 12 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10.50
11:10:13 PM 13 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 14 99.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 15 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 17 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 18 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 19 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 20 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 21 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 22 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 23 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 24 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 25 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 26 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
11:10:13 PM 27 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:10:13 PM 28 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
where
CPU – Processor number. The keyword all indicates that statistics are calculated as averages among all processors.
%user – Show the percentage of CPU utilization that occurred while executing at the user level (application).
%nice – Show the percentage of CPU utilization that occurred while executing at the user level with nice priority.
%sys – Show the percentage of CPU utilization that occurred while executing at the system level (kernel). Note that this does not include time spent servicing interrupts or softirqs.
%iowait – Show the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.
%irq – Show the percentage of time spent by the CPU or CPUs to service interrupts.
%soft – Show the percentage of time spent by the CPU or CPUs to service softirqs. A softirq (software interrupt) is one of up to 32 enumerated software interrupts which can run on multiple CPUs at once.
%steal – Show the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
%idle – Show the percentage of time that the CPU or CPUs were idle and the system did not have an outstanding disk I/O request.
intr/s – Show the total number of interrupts received per second by the CPU or CPUs.
2. Getting average from mpstat
To get an average you have to invoke the interval and count argument. In the example, interval is 2 second for 5 count
# mpstat -P ALL 2 5
At the end of the statistics report, you will see an average
Average: CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
Average: all 40.76 0.00 0.03 0.00 0.00 0.00 0.00 59.21 1047.50
Average: 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1000.60
Average: 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 2 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 4 99.90 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00
Average: 5 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 6 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 7 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 8 0.00 0.00 0.10 0.00 0.00 0.00 0.00 99.90 17.30
Average: 9 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 11 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 12 99.90 0.00 0.00 0.00 0.00 0.10 0.00 0.00 29.70
Average: 13 0.00 0.00 0.10 0.00 0.00 0.00 0.00 99.90 0.00
Average: 14 99.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00
Average: 15 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 17 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 18 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 19 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 20 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 21 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 22 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 23 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 24 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 25 99.90 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00
Average: 26 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 27 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 28 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 29 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00
Average: 30 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 0.00