
This is an interesting 3-part article on OpenVINO Deep Learning Workbench.
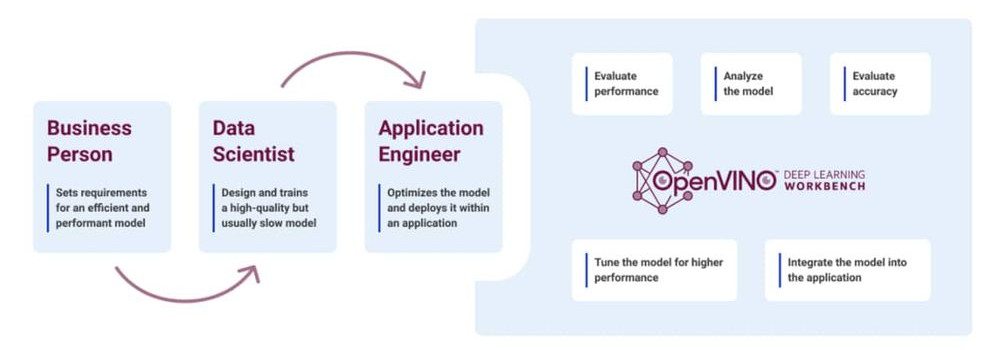
Pruning deep learning models, combining network layers, developing for multiple hardware targets—getting from a trained deep learning model to a ready-to-deploy inference model seems like a lot of work, which it can be if you hand code it.
The No-Code Approach to Deploying Deep Learning Models on Intel® Hardware
With Intel® tools you can go from trained model to an optimized, packaged inference model entirely online without a single line of code. In this article, we’ll introduce you to the Intel® toolkits for deep learning deployments, including the Intel® Distribution of OpenVINO™ toolkit and Deep Learning Workbench. After that, we’ll get you signed up for a free Intel DevCloud for the Edge account so that you can start optimizing your own inference models.
For more information, see The No-Code Approach to Deploying Deep Learning Models on Intel® Hardware
