
A group of researchers led by Martin Schulz of the Leibniz Supercomputing Center (Munich) presented a paper in which they argue HPC architectural landscape of High-Performance Computing (HPC) is undergoing a seismic shift.
The Full Article is taken from Summer Reading: “High-Performance Computing Is at an Inflection Point”
4 Guiding Principles for the Future of HPC Architecture
- Energy consumption is no longer merely a cost factor but also a hard feasibility constraint for facilities.
- Specialization is key to further increase performance despite stagnating frequencies and within limited energy bands.
- A significant portion of the energy budget is spent moving data and future architectures must be designed to minimize such data movements.
- Large-scale computing centers must provide optimal computing resources for increasingly differentiated workloads.
Ideas Snippets – Integrated Heterogeneity
Integrated Heterogenous Systems are a promising alternative, which integrate multiple specialized architectures on a single node while keeping the overall system architecture a homogeneous collection of mostly identical nodes. This allows applications to switch quickly between accelerator modules at a fine-grained scale, while minimizing the energy cost and performance overhead, enabling truly heterogeneous applications.
Integrated HPC Systems and How They will Change HPC System Operations
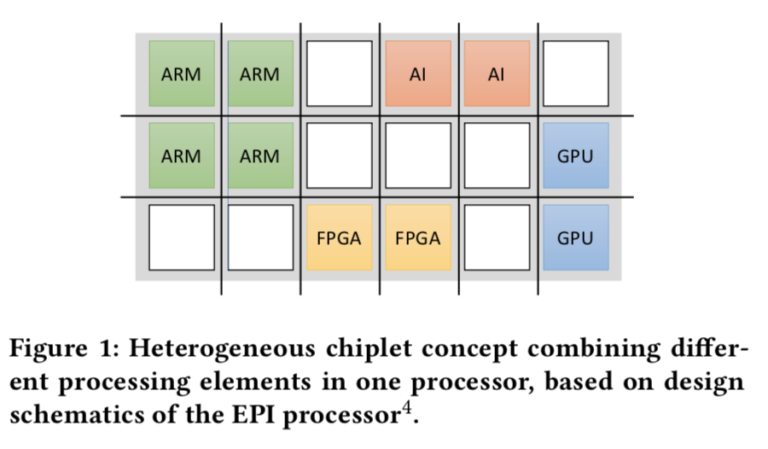
Ideas Snippets – Challenges of a Integrated Heterogeneity
a single application is likely not going use all specialized compute elements at the same time, leading to idle processing elements. Therefore, the choice of the best-suited accelerator mix is an important design criterion during procurement, which can only be achieved via co-design between the computer center and its users on one side and the system vendor on the other. Further, at runtime, it will be important to dynamically schedule and power the respective compute resources. Using power overprovisioning, i.e., planning for a TDP and maximal node power that is reached with a subset of dynamically chosen accelerated processing elements, this can be easily achieved, but requires novel software approaches in system and resource management.”
They note the need for programming environments and abstractions to exploit the different on-node accelerators. “For widespread use, such support must be readily available and, in the best case, in a unified manner in one programming environment. OpenMP, with its architecture-agnostic target concept, is a good match for this. Domain-specific frameworks, as they are, e.g., common in AI, ML or HPDA (e.g., Tensorflow, Pytorch or Spark), will further help to hide this heterogeneity and help make integrated platforms accessible to a wide range of users
HPCWire – Summer Reading: “High-Performance Computing Is at an Inflection Point”
Idea Snippets – Coping with Idle Periods among different Devices (Project Regale)
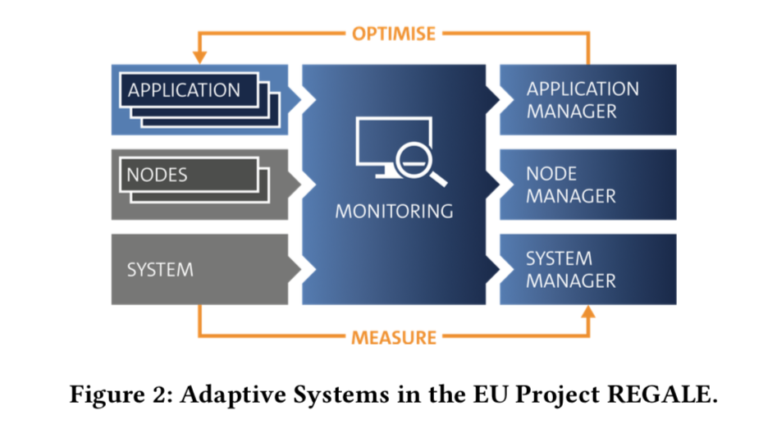
Application Level. Changing application resources in terms of number and type of processing elements dynamically.
Node Level. Changing node settings, e.g. power/energy consumption via techniques like DVFS or power capping as well as node level partitioning of memory, caches, etc.
System Level. Adjusting system operation based on work- loads or external inputs, e.g., energy prices or supply levels.
HPCWire – Summer Reading: “High-Performance Computing Is at an Inflection Point”

Reblogged this on Bits and Dragons and commented:
A fascinating approach. Reblogged for my reference and in case you don’t follow already the Linux Cluster blog. 😉
LikeLike