Abstract Taken form Myths and Legends in High-Performance Computing
In this humorous and thought provoking article, we discuss certain myths and legends that are folklore among members of the high-performance computing community. We collected those myths from conversations at conferences and meetings, product advertisements, papers, and other communications such as tweets, blogs, and news articles within (and beyond) our community. We believe they represent the zeitgeist of the current era of massive change, driven by the end of many scaling laws such as ennard scaling and Moore’s law. While some laws end, new directions open up, such as algorithmic scaling or novel architecture research. However, these myths are rarely based on scientific facts but often on some evidence or argumentation. In fact, we believe that this is the very reason for the existence of many myths and why they cannot be answered clearly. While it feels like there should be clear answers for each, some may remain endless philosophical debates such as the question whether Beethoven was better than Mozart. We would like to see our collection of myths as a discussion of possible new directions for research and industry investment
Myths and Legends in High-Performance Computing
The article addresses the follow myths
- Myth 1: Quantum Computing Will Take Over HPC!
- Myth 2: Everything Will Be Deep Learning!
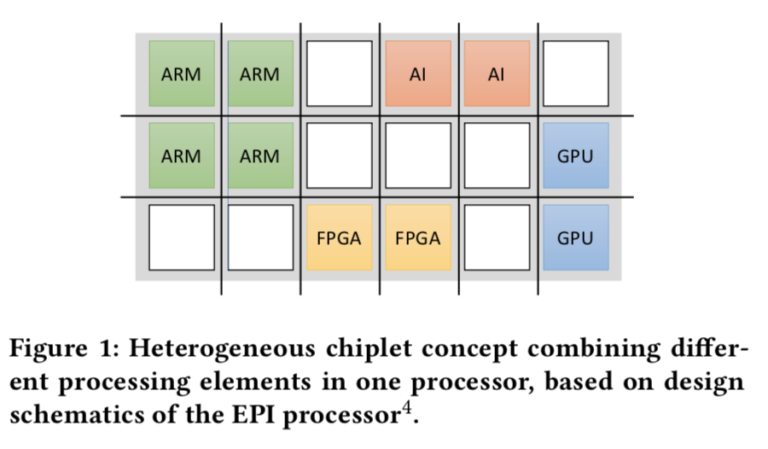
- Myth 3: Extreme Specialization as Seen in Smartphones Will Push Supercomputers Beyond Moore’s Law!
- Myth 4: Everything Will Run on Some Accelerator!
- Myth 5: Reconfigurable Hardware Will Give You 100X Speedup!
- Myth 6: We Will Soon Run at Zettascale!
- Myth 7: Next-Generation Systems Need More Memory per Core!
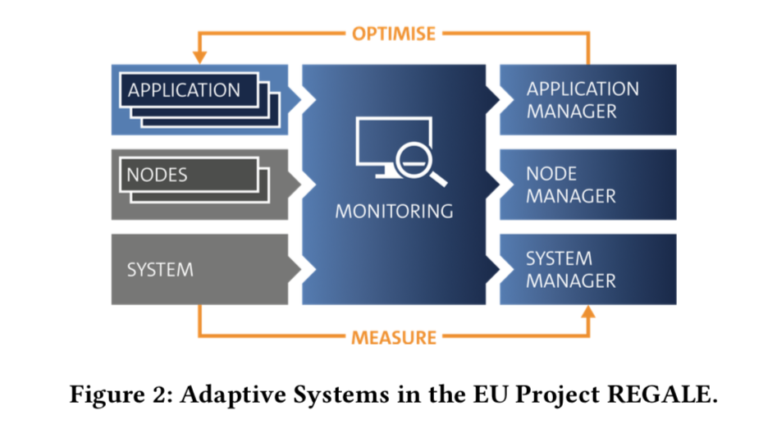
- Myth 8: Everything Will Be Disaggregated!
- Myth 9: Applications Continue to Improve, Even on Stagnating Hardware!
- Myth 10: Fortran Is Dead, Long Live the DSL!
- Myth 11: HPC Will Pivot to Low or Mixed Precision!
- Myth 12: All HPC Will Be Subsumed by the Clouds!