This Website is important to get the right mapping for the Version Running Mapping from Intel. This is Good Information
Just took a snapshot of Intel 2018 to 2020

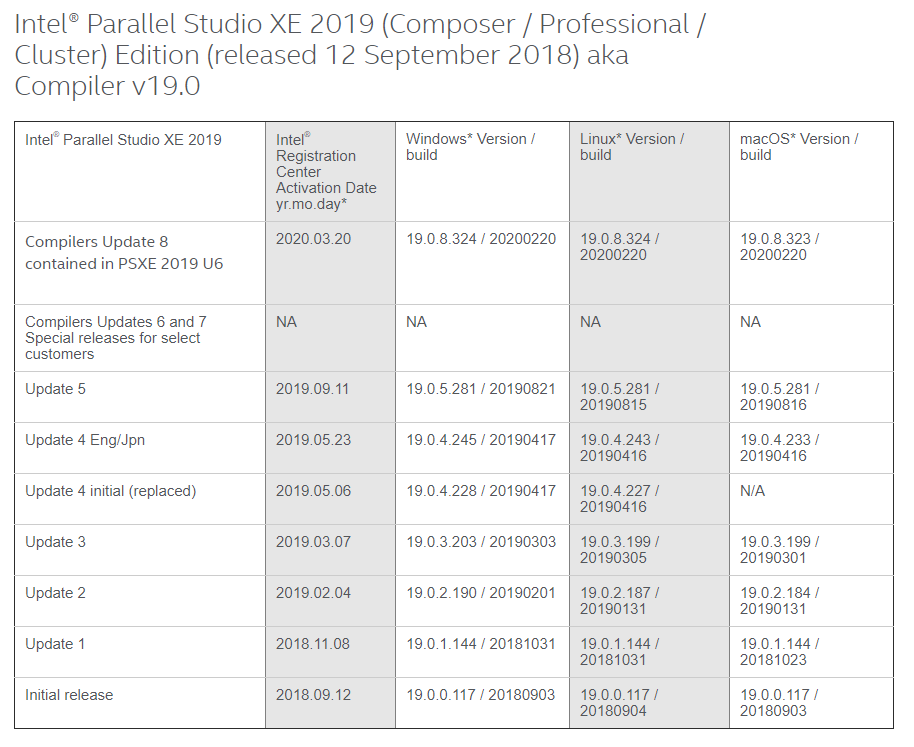


This Website is important to get the right mapping for the Version Running Mapping from Intel. This is Good Information
Just took a snapshot of Intel 2018 to 2020
Taken from Intel Performance Libraries, Intel® MPI Library Over Libfabric*

What is Libfabric?
Libfabric is a low-level communication abstraction for high-performance networks. It hides most transport and hardware implementation details from middleware and applications to provide high-performance portability between diverse fabrics.
Using the Intel MPI Library Distribution of Libfabric
By default, mpivars.sh sets the environment to the version of libfabric shipped with the Intel MPI Library. To disable this, use the I_MPI_OFI_LIBRARY_INTERNAL environment variable or -ofi_internal (by default ofi_internal=1)
# source /usr/local/intel/2018u3/impi/2018.3.222/bin64/mpivars.sh -ofi_internal=1
# I_MPI_DEBUG=4 mpirun -n 1 IMB-MPI1 barrier[0] MPI startup(): libfabric version: 1.7.2a-impi
[0] MPI startup(): libfabric provider: verbs;ofi_rxm
[0] MPI startup(): Rank Pid Node name Pin cpu
[0] MPI startup(): 0 130358 hpc-n1 {0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,
30,31}
#------------------------------------------------------------
# Intel(R) MPI Benchmarks 2019 Update 4, MPI-1 part
#------------------------------------------------------------
# Date : Thu May 20 12:57:03 2021
# Machine : x86_64
# System : Linux
# Release : 3.10.0-693.el7.x86_64
# Version : #1 SMP Tue Aug 22 21:09:27 UTC 2017
# MPI Version : 3.1
# MPI Thread Environment:
# Calling sequence was:
# IMB-MPI1 barrier
# Minimum message length in bytes: 0
# Maximum message length in bytes: 4194304
#
# MPI_Datatype : MPI_BYTE
# MPI_Datatype for reductions : MPI_FLOAT
# MPI_Op : MPI_SUM
#
#
# List of Benchmarks to run:
# Barrier
#---------------------------------------------------
# Benchmarking Barrier
# #processes = 1
#---------------------------------------------------
#repetitions t_min[usec] t_max[usec] t_avg[usec]
1000 0.08 0.08 0.08
# All processes entering MPI_Finalize
Changing the -ofi_internal=0
# source /usr/local/intel/2018u3/impi/2018.3.222/bin64/mpivars.sh -ofi_internal=0
# I_MPI_DEBUG=4 mpirun -n 1 IMB-MPI1 barrier[0] MPI startup(): libfabric version: 1.1.0-impi
[0] MPI startup(): libfabric provider: mlx
.....
.....Common OFI Controls
To select the OFI provider from the libfabric library, you can use definte the name of the OFI Provider to load
export I_MPI_OFI_PROVIDER=tcpLogging Interfaces
FI_LOG_LEVEL=<level> controls the amount of logging data that is output. The following log levels are defined:
References:
Simple, Short and Good explanation…..
What is RELION?
RELION (REgularized LIkelihood OptimizatioN) is an open-source program for the refinement of macromolecular structures by single-particle analysis of electron cryomicroscopy (cryo-EM) data
RELION (REgularized LIkelihood OptimizatioN) implements an empirical Bayesian approach for analysis of electron cryo-microscopy (Cryo-EM)
RELION provides refinement methods of singular or multiple 3D reconstructions as well as 2D class averages
RELION is an important tool in the study of living cells
HPC-AI Advisory Council
Performance Analysis Summary
(from Article See RELION – Performance Benchmark and Profiling)
RELION performance testing
RELION Profile
References:
The article is taken from Centrify Knowledge Base (KB-1425): adclient goes into “disconnected mode”
Causes
There are several reasons why adclient can goes into disconnect mode. According to the article, it could be due to
Solution:
In Linux, you can restart the Centrify DirectControl Service
# /etc/init.d/centrifydc restart
Stopping Centrify DirectControl: [ OK ]
Starting Centrify DirectControl: [ OK ]
adclient state is: connected
OR you can reset computer object on UNIX/LINUX client:
# adkeytab -r -u administrator@yourdomain.comNotes:
Machine password renewal can be turned off (for testing purposes only) in /etc/centrifydc/centrifydc.conf by making the following change and running adreload. (Default is 28 days)
adclient.krb5.password.change.interval: 0

This is an interesting writeup on various ways to speed up your application. This is useful if you are getting into HPC for the first time. The author POR IVICA BOGOSAVLJEVIĆ suggested various ways
References:

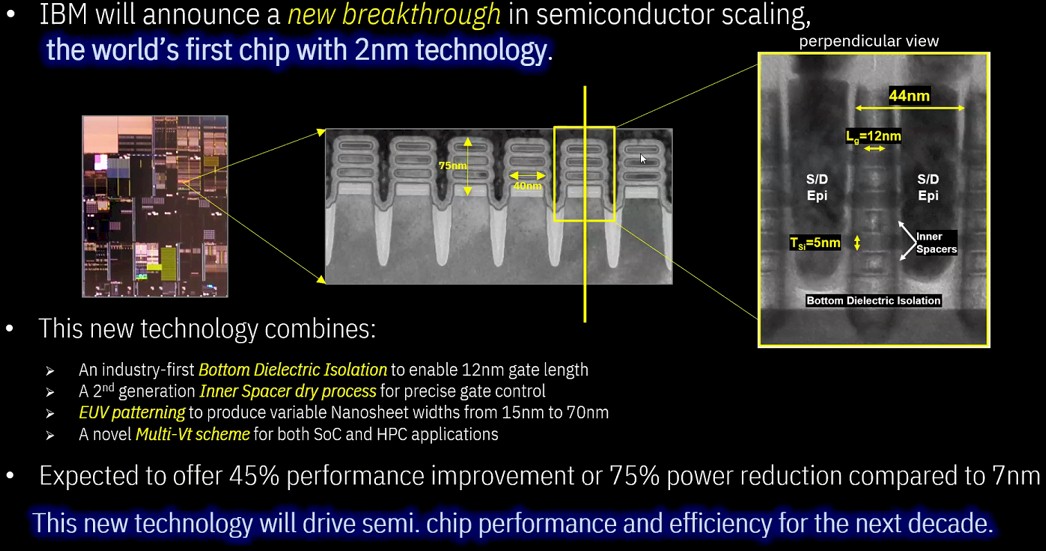
IBM claims that the 2nm chip could achieve 45 percent higher performance, or 75 percent lower energy use, than “today’s most advanced 7nm node chips.”
Darío Gil, SVP and director of IBM Research.

A single human hair spans a whopping 50,000-75,000 nanometers. A human red blood cell is 6,000-8,000nm. Covid-19 is 50-140nm…….. To build nodes 3nm and below requires extremely expensive and sensitive equipment, and a rethink on how nodes are laid out – hence the different metrics now used to measure smaller nodes.
DataDynamics (https://www.datacenterdynamics.com/en/news/ibm-claims-to-have-made-the-worlds-first-2nm-chip/)
References
GPU computing is a widely adopted technology that uses the power of GPUs to accelerate computationally intensive workflows. Since 2010, Parallel Computing Toolbox has provided GPU Computing support for MATLAB.
