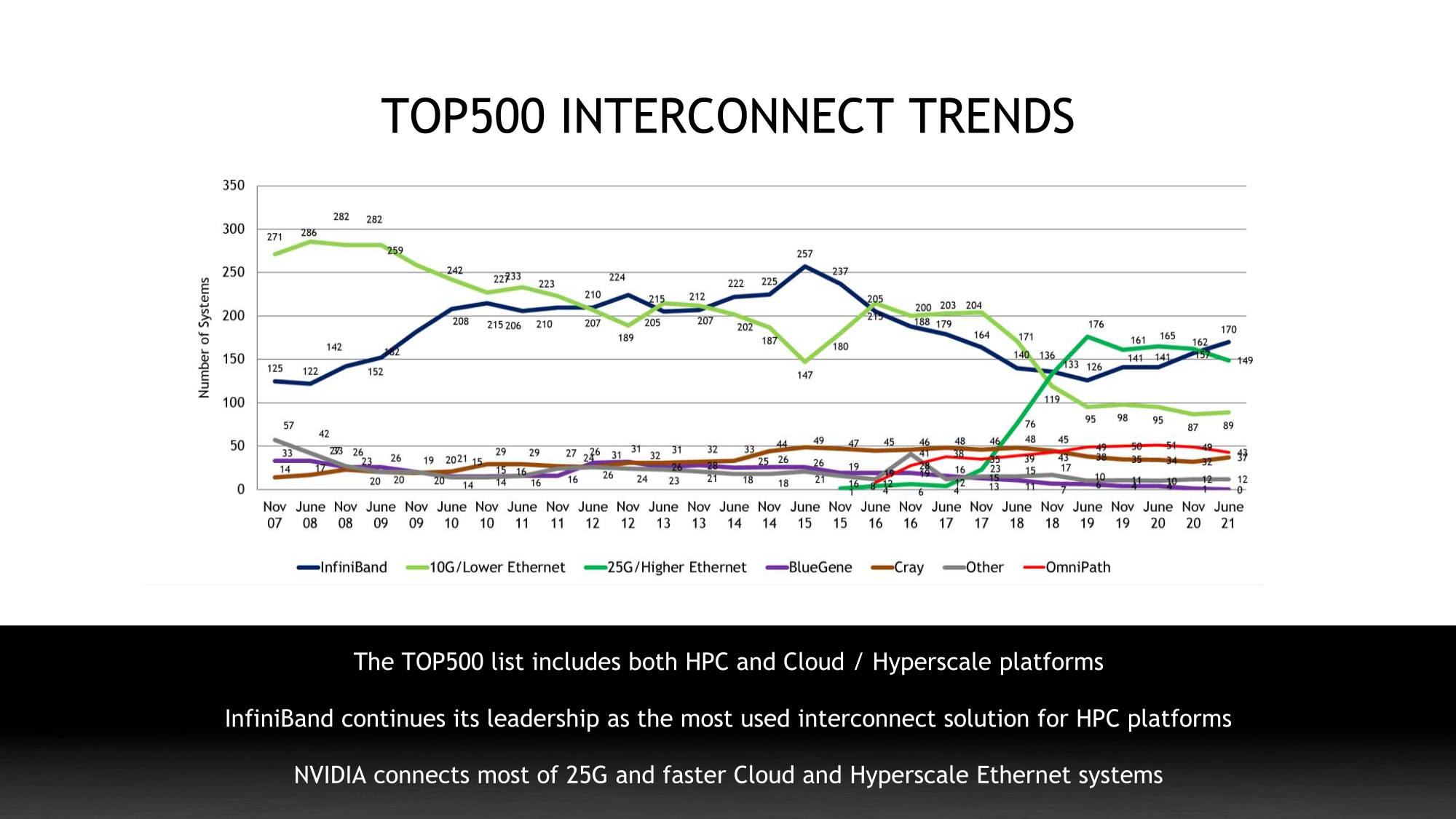
Published twice a year and publicly available at www.top500.org, the TOP500 supercomputing list ranks the world’s most powerful computer systems according to the Linpack benchmark rating system.
Summary of Findings for Nvidia Networking.
- NVIDIA GPU or Network (InfiniBand, Ethernet) accelerate 342 systems or 68% of overall TOP500 systems
- InfiniBand accelerates seven of the top ten supercomputers in the world
- NVIDIA BlueField DPU and HDR InfiniBand Networking accelerate the world’s 1st academic cloud-native supercomputer at Cambridge University
- NVIDIA InfiniBand and Ethernet networking solutions connect 318 systems or 64% of overall TOP500 platforms
- InfiniBand accelerates 170 systems, 21% growth compared to June 2020 TOP500 list
- InfiniBand accelerates #1, #2 supercomputers in the US, #1 in China, #1, #2 and #3 in Europe
- NVIDIA 25 gigabit and faster Ethernet solutions connect 62% of total Ethernet systems