For workload management and resource scheduling, NCAR uses Altair PBS Professional to exploit features like cloud bursting, fairshare, power-user and maintenance reservations, resource assignment with control groups, high-throughput hierarchical scheduling, green provisioning, and energy-aware scheduling.
This presentation by Irfan Elahi, Brian Vanderwende, and John Blaas from the National Center for Atmospheric Research (NCAR) was aired during the 2021 Altair HPC Summit
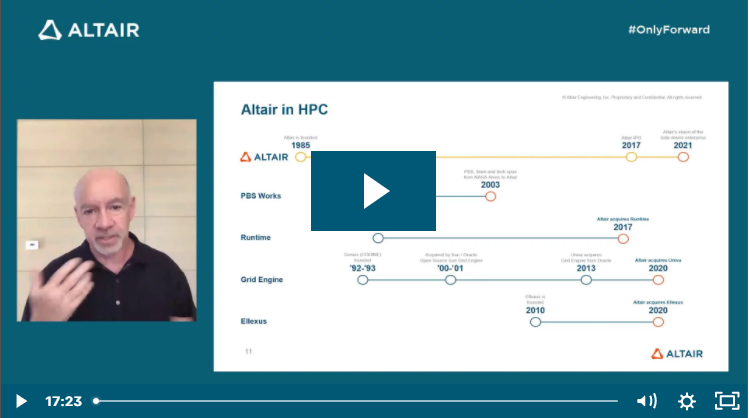
The presentation by Altair Founder, Chairman, and CEO James Scapa outlines Altair’s vision for the convergence of HPC, artificial intelligence, and simulation.
Libfabric is a low-level communication abstraction for high-performance networks. It hides most transport and hardware implementation details from middleware and applications to provide high-performance portability between diverse fabrics.
Using the Intel MPI Library Distribution of Libfabric
By default, mpivars.sh sets the environment to the version of libfabric shipped with the Intel MPI Library. To disable this, use the I_MPI_OFI_LIBRARY_INTERNAL environment variable or -ofi_internal (by default ofi_internal=1)
To select the OFI provider from the libfabric library, you can use definte the name of the OFI Provider to load
export I_MPI_OFI_PROVIDER=tcp
Logging Interfaces
FI_LOG_LEVEL=<level> controls the amount of logging data that is output. The following log levels are defined:
Warn: Warn is the least verbose setting and is intended for reporting errors or warnings.
Trace: Trace is more verbose and is meant to include non-detailed output helpful for tracing program execution.
Info: Info is high traffic and meant for detailed output.
Debug: Debug is high traffic and is likely to impact application performance. Debug output is only available if the library has been compiled with debugging enabled.
RELION (REgularized LIkelihood OptimizatioN) is an open-source program for the refinement of macromolecular structures by single-particle analysis of electron cryomicroscopy (cryo-EM) data
RELION (REgularized LIkelihood OptimizatioN) implements an empirical Bayesian approach for analysis of electron cryo-microscopy (Cryo-EM)
RELION provides refinement methods of singular or multiple 3D reconstructions as well as 2D class averages
RELION is an important tool in the study of living cells
There are several reasons why adclient can goes into disconnect mode. According to the article, it could be due to
Replication Delays
Expired Computer Password or not renewed or out of sync
Solution:
In Linux, you can restart the Centrify DirectControl Service
# /etc/init.d/centrifydc restart
Stopping Centrify DirectControl: [ OK ]
Starting Centrify DirectControl: [ OK ]
adclient state is: connected
OR you can reset computer object on UNIX/LINUX client:
# adkeytab -r -u administrator@yourdomain.com
Notes:
Machine password renewal can be turned off (for testing purposes only) in /etc/centrifydc/centrifydc.conf by making the following change and running adreload. (Default is 28 days)
This is an interesting writeup on various ways to speed up your application. This is useful if you are getting into HPC for the first time. The author POR IVICA BOGOSAVLJEVIĆ suggested various ways
AMD EPYC™ Server Virtualization TCO Estimation Tool See the potential value AMD EPYC™ CPUs may deliver for your datacenter. Input your VM requirements and environment factors like power, real estate cost, select your virtualization license, and more. Compare your current x86 based server solution to a solution powered by AMD EPYC™ processors.
AMD EPYC™ Bare Metal TCO Estimation Tool Discover the potential value that AMD EPYC™ CPUs can deliver for your bare metal server environment. Compare by server count, performance, or total budget. Then select your filter, your processor comparisons, and system memory requirements. Choose 3, 4, or 5 year time frames for your AMD EPYC™ Bare Metal TCO estimation.
AMD Cloud Cost Advisor Discover the potential value AMD EPYC™ CPUs bring to the cloud with the latest cost analysis tool. AMD Cloud Cost Advisor helps with real-time insights into estimated cost savings when switching to cloud instances powered by AMD within the same cloud service provider.