When you do a “/usr/local/cuda-10.1/extras/demo_suite/deviceQuery”. You might get the errors seemed above
[root@node1 ~]# /usr/local/cuda-10.1/extras/demo_suite/deviceQuery /usr/local/cuda-10.1/extras/demo_suite/deviceQuery Starting... CUDA Device Query (Runtime API) version (CUDART static linking) cudaGetDeviceCount returned 35 -> CUDA driver version is insufficient for CUDA runtime version Result = FAIL
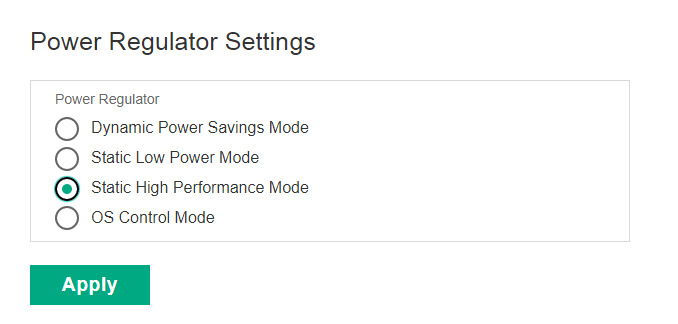
The Issue may cause some confusion. It is not your libraries. But the it is the Power Setting at the BIOS. Most Servers are configured to be balanced. But for GPGPU, you need to put Power to “Maximum Performance”. For example, for HPE Server, you should put “Static High Performance Mode”