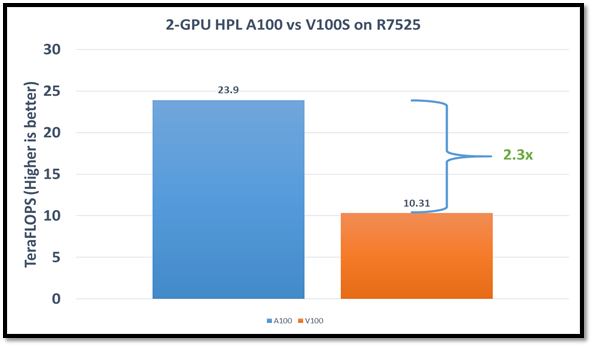
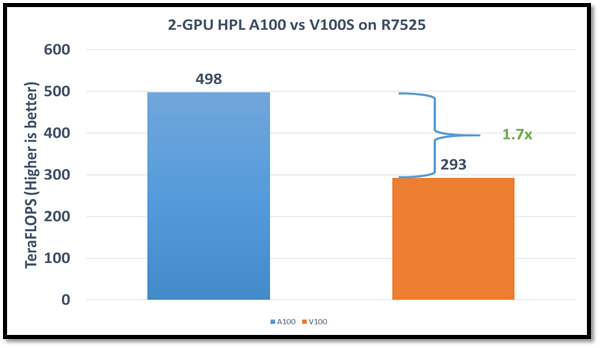
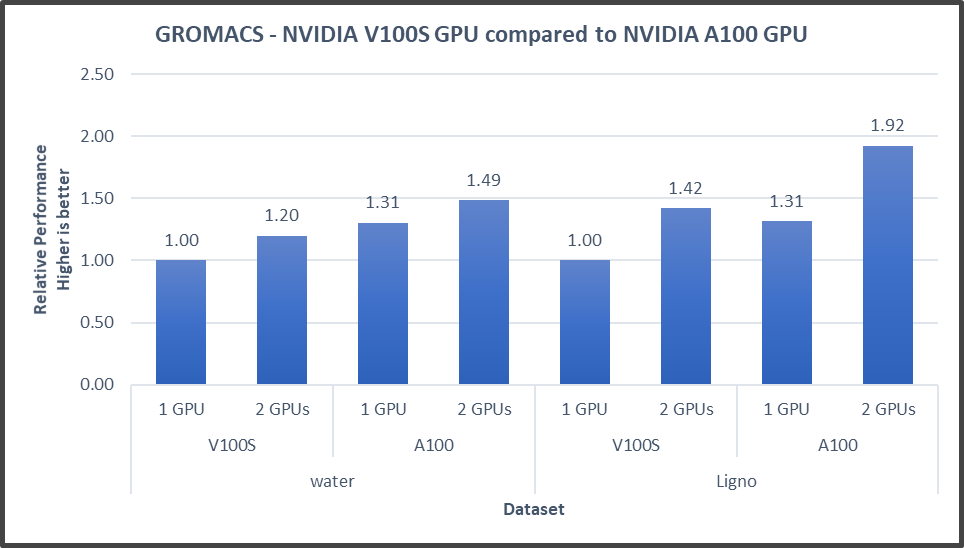
Articles from: Deep Learning Training Performance on Dell EMC PowerEdge R7525 Servers with NVIDIA A100 GPUs
CUDA Basic Linear Algebra

- For FP16, the HGEMM TFLOPs of the NVIDIA A100 GPU is 2.27 times faster than the NVIDIA V100S GPU.
- For FP32, the SGEMM TFLOPs of the NVIDIA A100 GPU is 1.3 times faster than the NVIDIA V100S GPU.
- For TF32, performance improvement is expected without code changes for deep learning applications on the new NVIDIA A100 GPUs. This expectation is because math operations are run on NVIDIA A100 Tensor Cores GPUs with the new TF32 precision format. Although TF32 reduces the precision by a small margin, it preserves the range of FP32 and strikes an excellent balance between speed and accuracy. Matrix multiplication gained a sizable boost from 13.4 TFLOPS (FP32 on the NVIDIA V100S GPU) to 86.5 TFLOPS (TF32 on the NVIDIA A100 GPU).
MLPerf Training v0.7 ResNet-50

Both runs using two NVIDIA A100 GPUs and two NVIDIA V100S GPUs converged at the 40th epoch. The NVIDIA A100 run took 166 minutes to converge, which is 1.8 times faster than the NVIDIA V100S run. Regarding throughput, two NVIDIA A100 GPUs can process 5240 images per second, which is also 1.8 times faster than the two NVIDIA V100S GPUs.