Storage
Portworx Lightboard Sessions: Deployment Modes (Hyperconverged, Disaggregated)
In this short video you will learn the two main deployment modes in which Portworx can be installed on your infrastructure.
Portworx Lightboard Sessions: Understanding Storage Pools
In this short video, learn how Portworx clusters infrastructure together into classified storage resource pools for applications.
Portworx Lightboard Sessions: Portworx 101 (Overview)
Learn the basics of Portworx and how it can enable your stateful workloads. This video will discuss the largest fragments of the Portworx platform and how it creates a global namespace to enable virtual volumes for containers.
Portworx Lightboard Sessions: Why choose Portworx?
Portworx is the leading container data management solution for Kubernentes. This short video will explain the Portworx value proposition along with some of the differentiating features such as data mobility, application awareness and infrastructure independence.
RapidFile Toolkit v2.0 for FlashBlade
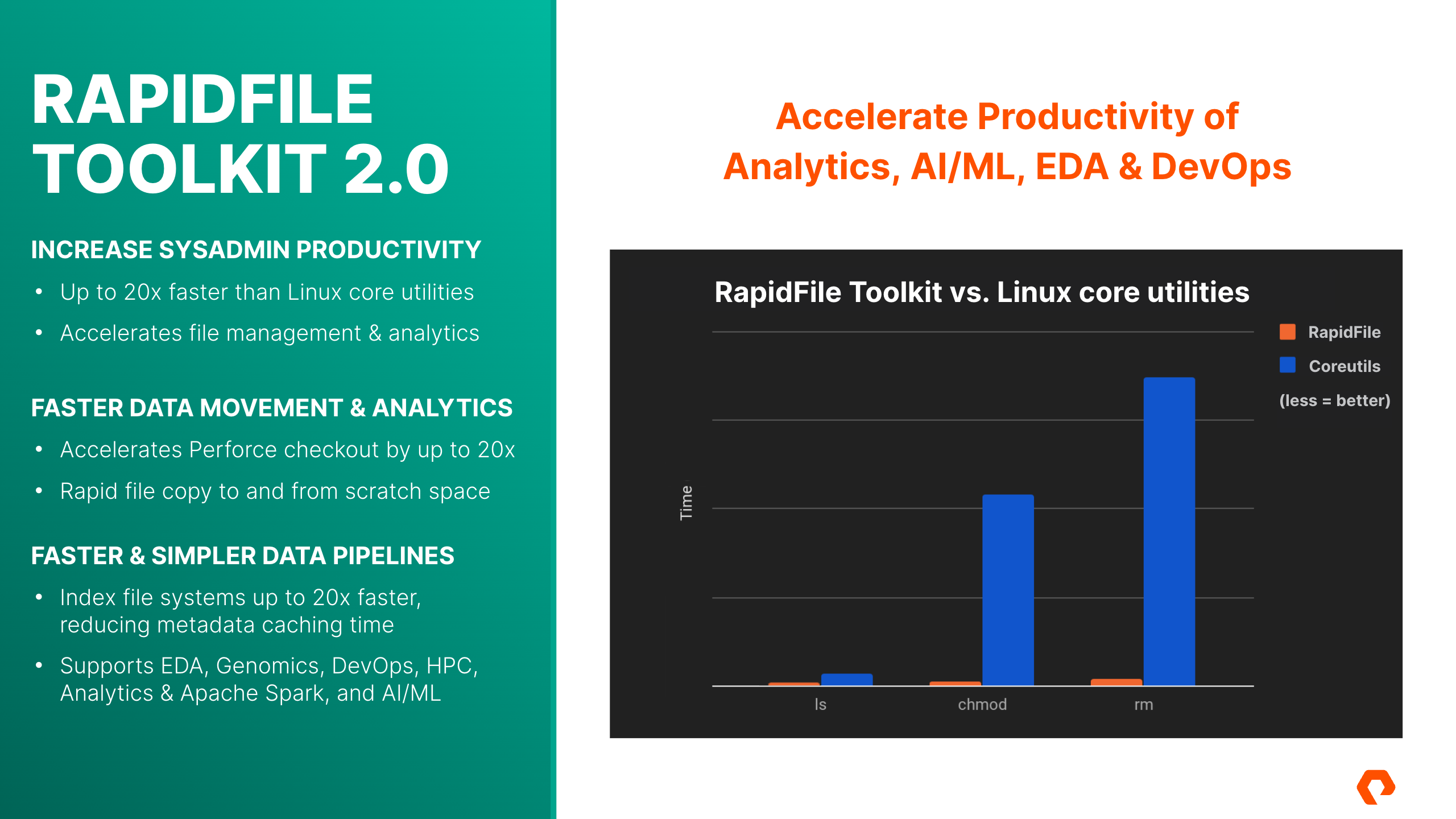
What is RapidFile Toolkit?
RapidFile Toolkit is a set of supercharged tools for efficiently managing millions of files using familiar Linux command line interfaces. RapidFile Toolkit is designed from the ground up to take advantage of Pure Storage FlashBlade’s massively parallel, scale-out architecture, while also supporting standard Linux file systems. RapidFile Toolkit can serve as a high performance, drop-in replacement for Linux commands in many common scenarios, which can increase employee efficiency, application performance, and business productivity. RapidFile Toolkit is available to all Pure Storage customers.
RapidFile
Benefits of RapidToolkit according to the Site
Increase SysAdmin Productivity
- Up to 20X faster than Linux Core Utilities
- Accelerates file management and analytics
Faster Data Movement & Analytics
- Accelerates Perforce Checkout by up to 20X
- Rapid file copy to and from scratch space
Faster & Simpler Data Pipelines
- Indexing files systems up to 20X faster, reducing metadata caching time
- Support EDA, Genomics, DevOps, HPC, Analytics & Apache Spark and AI/ML
Commands
| Linux commands | RapidFile Toolkit v2.0 | Description |
|---|---|---|
| ls | pls | Lists files & directories |
| find | pfind | Finds matching files |
| du | pdu | Summarizes file space usage |
| rm | prm | Removes files & directories |
| chown | pchown | Changes file ownership |
| chmod | pchmod | Changes file permissions |
| cp | pcopy | Copies files & directories |
To Download, you have to be Pure Storage Customers and Partners.
Download URL (login required):
Configuring NVMeoF RoCE For SUSE 15

The blog is taken from Configuring NVMeoF RoCE For SUSE 15.
The purpose of this blog post is to provide the steps required to implement NVMe-oF using RDMA over Converged Ethernet (RoCE) for SUSE Enterprise Linux (SLES) 15 and subsequent releases.
The blog is taken from Configuring NVMeoF RoCE For SUSE 15.
An important item to note is that RoCE requires a lossless network, requiring global pause flow control or PFC to be configured on the network for smooth operation.
All of the below steps are implemented using Mellanox Connect-X4 adapters.
Pawsey Supercomputing Centre deploy 130 PB of Multi-Tier Storage with Ceph

Article is taken from HPCWire “Pawsey Supercomputing Centre to Deploy 130PB of Multi-Tier Storage“
The system has been designed to be both cost-effective and scalable.
HPCWire “Pawsey Supercomputing Centre to Deploy 130PB of Multi-Tier Storage”
To maximise value, Pawsey has invested in Ceph, software for building storage systems out of generic hardware, and has built the online storage infrastructure around Ceph in-house. As more servers are added, the online object storage becomes more stable, resilient, and even faster.
“That’s how we were able to build a 60 PB system on this budget,” explains Gray.
“An important part of this long-term storage upgrade was to demonstrate how it can be done in a financially scalable way. In a world of mega-science projects like the Square Kilometre Array, we need to develop more cost-effective ways of providing massive storage.”
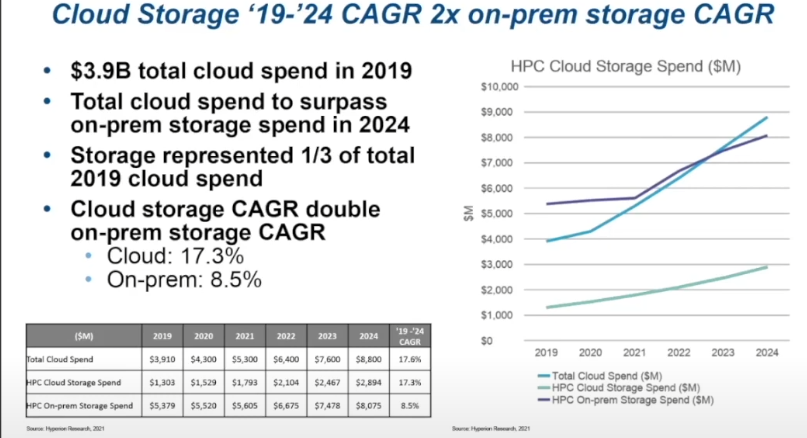
Rapid Growth in HPC Storage
The Article is taken from On-Prem No Longer Centre Stage for Broader HPC Storage
AI/ML, more sophisticated analytics, and larger-scale HPC problems all bode well for the on-prem storage market in high performance computing (HPC) and are an even bigger boon for cloud storage vendors.
Nossokoff points to several shifts in the storage industry and among the top supercomputing sites, particularly in the U.S. that reflect changing priorities with storage technologies, especially with the mixed file problems AI/ML introduce into the traditional HPC storage hierarchy. “We’re seeing a focus on raw sequential large block performance in terms of TB/s, high-throughput metadata and random small-block IOPS performance, cost-effective capacity for increasingly large datasets in all HPC workloads, and work to add intelligent placement of data so it’s where it needs to be.”
In addition to keeping pace with the storage tweaks to suit AI/ML as well as traditional HPC, there have been shifts in the vendor ecosystem this year as well. These will likely have an impact on what some of the largest HPC sites do over the coming years as they build and deploy their first exascale machines. Persistent memory is becoming more common, companies like Samsung are moving from NVMe to CXL, which is an indication of where that might fit in the future HPC storage and memory stack. Companies like Vast Data, which were once seen as an up and coming player in the on-prem storage hardware space for HPC transformed into a software company, Nossokoff says.
On-Prem No Longer Centre Stage for Broader HPC Storage – NextPlatform