
According to the project website, Linux Virtual Server (LVS) is a highly scalable and highly available server built on a cluster of real servers. The architecture of server cluster is fully transparent to end users, and the users interact with the cluster system as if it were only a single high-performance virtual server.
Much of the information is taken from the book “The Linux Enterprise Cluster” by Karl Cooper and the Project Website.
This diagram is taken from the project website which explain very clearly the purpose of this project.

The Linux Virtual Server (LVS) accepts all incoming client computer requests for services and decides which one in the cluster nodes will reply to the client. Some naming convention used by the LVS community
- Real Server refers to the nodes inside the an LVS Cluster
- Client Computer refers to computer outside the LVS Cluster
- Virtual IP (VIP) address refers to the IP address the Director uses to offer services to client computer. A single LVS Director can have multiple VIPS offering different services to client computerx. This is the only IP that the client computer needs to know to access to.
- Real IP (RIP) address refers to the IP Address used on the cluster node. Only the LVS Director is required to know the IP Addresses of this node
- Director IP (DIP) address refers to the IP address the LVS Director uses to connect to the RIP network. As requests from the client computer comes, they are forwarded to the client PCs. the VIP and DIP can be on the same NIC
- Client IP Address (CIP) address refers to the IP address of the client pc.
A. Types of LVS Clusters
The types of LVS Clusters are usually described by the type of forwarding method, the LVS Director uses to relay incoming requests to the nodes inside the cluster
- Network Address Translation (LVS-NAT)
- Direct routing (LVS-DR)
- IP Tunnelling (LVS-TUN)
According to the Book “The Linux Enterprise Cluster by Karl Cooper”, the best forwarding method to use with a Linux Enterprise Cluster is a LVS-DR. The easier to build is LVS-NAT. The LVS-TUN is generally not in use for mission critical applications and mentioned for the sake of competencies.
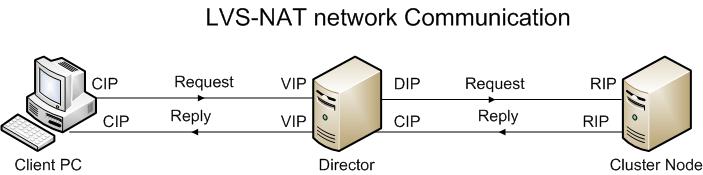
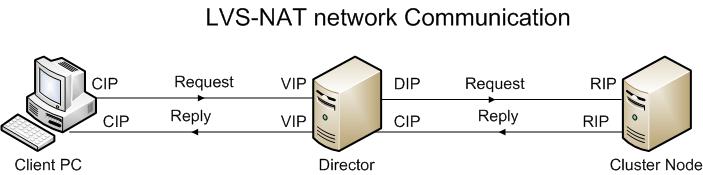
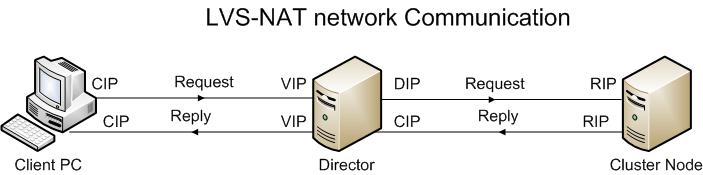
A1. LVS-NAT Translation

In a LVS-NAT setup, the Director uses the Linux kernel’s ability (from the kernel’s filter code) to translate IP Addresses and ports as packets pass through the kernel.
From the diagram above, the client send a request and is sent to the Director on its VIP. The Director redirects the request to the RIP of the Cluster Node. The Cluster Node reply back via its RIP to the Director. The Director convert the cluster node RIP into the VIP owned by the Director and return reply to the client.
Some basic notes on the LVS-NAT
- The Director intercepts all communication from clients to the cluster nodes
- The cluster nodes uses the Director DIP as their default gateway for reply packets to the client computers
- The Director can remap network port numbers
- Any operating system can be used inside the cluster
- Network or the Director may be a bottleneck. It is mentioned that a 400Mhz can saturate a 100MB connection
- It may be difficult to administer the cluster node as the administrator must enter the cluster node via the Director. Of course you can do a bit of network and firewall configuration to circumvent the limitation
A2 LVS-DR (Direct Routing)
 s
s
In a LVS-DR setup, the Director for towards all the incoming requests to the nodes inside the cluster, but the nodes inside the cluster send their replies directly back to the client computer.
From the diagram, the client send a request and is send to the Director on its VIP. The Director redirects the request to the RIP of the Cluster Node. The cluster node reply back directly to the client and the packet uses the VIP as its source IP Addresses. The Client is fooled into thinking it is talking to a single computer (Director)
Some Basic properties of the LVS-DR
- The cluster nodes must be on the same segment as the Director
- The Director intercepts inbound communication but not outbound communication between clients and the real servers
- The cluster node do not use the Director as the default gateway for reply packets to the client
- The Director cannot remap network port number
- Most operating systems can be used on the real server inside the cluster. However the Operating System must be capable of configuring the network interface to avoid replying to ARP broadcasts.
- If the Director fails, the cluster nodes becomes distributed servers each with its own IP Addresses. You can “save” the situation by using Round-Robin DNS to hand out the RIP addresses for each cluster node. Alternatively, you can “save” the situation by asking the users to connect to the cluster node directly.
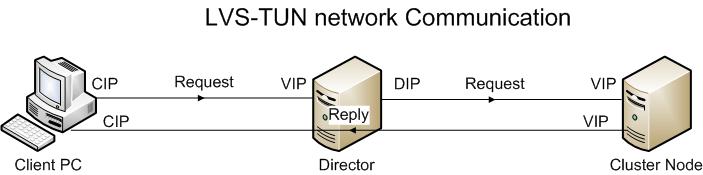
A3 LVS-TUN (IP Tunnelling)

IP tunnelling ca be used to forward packets from one subnet ot virtual LAN (VLAN) to another subnet or VLAN even when the packets must pass through another network. Building on the IP Tunnelling capability that is part of the Linux Kernel, the LVS-TUN forwarding method. The LVS-TUN forwarding method allows you to place the cluster nodes on a cluster network that is not on the same network segment as the Director.
The LVS-TUN enhances the capability of the LVS-DR method of packet forwrding by encapsulating inbound requests for cluster service from the client computers so that they can forwarded to cluster nodes that are no on the same physical network segment as the Director.This is done by encapsulating one packet inside another packet.
Basic Properties of LVS-TUN
- The cluster nodes do not need to be on the same physical network segment as the Director
- The RIP addresses must not be private IP Addresses
- Return packet must not go through the Director.
- The Director cannot remap network port number
- Only Operating Systems that supports the IP tunnelling protocol can be the servers inside the cluster.
- The LVS-TUN is less reliable than the LVD-DR as anything that breaks the connection between the Director and the cluster nodes will drop all client connections.
For more information on LVS Scheduling methods, see Linux Virtual Server Scheduling Methods Blog entry


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}