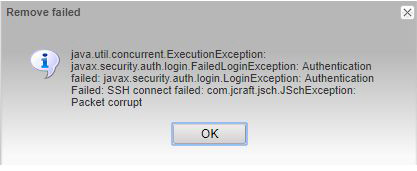
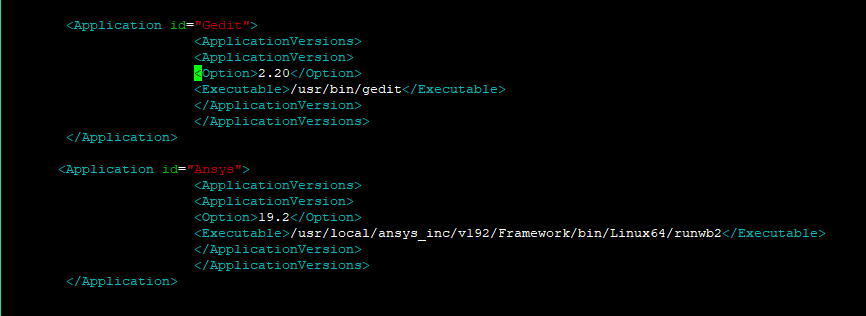
Check for the Visualisation Node configuration
# qmgr -c " p n VizSvr1"1. At the Node Configuration at PBS-Professional, the GPU Chunk (“ngpus”) is 10.
#
# Create nodes and set their properties.
#
#
# Create and define node VizSvr1
#
create node VizSvr1
set node VizSvr1 state = free
set node VizSvr1 resources_available.allows_container = False
set node VizSvr1 resources_available.arch = linux
set node VizSvr1 resources_available.host = VizSvr1
set node VizSvr1 resources_available.mem = 791887872kb
set node VizSvr1 resources_available.ncpus = 24
set node VizSvr1 resources_available.ngpus = 10
set node VizSvr1 resources_available.vnode = VizSvr1
set node VizSvr1 queue = iworkq
set node VizSvr1 resv_enable = True2. At the Queue Level, notice that the gpu chunk (“ngpus”) is 10 and cpu-chunk is 2
[root@scheduler1 ~]# qmgr
Max open servers: 49
Qmgr: p q iworkq#
# Create queues and set their attributes.
#
#
# Create and define queue iworkq
#
create queue iworkq
set queue iworkq queue_type = Execution
set queue iworkq Priority = 150
set queue iworkq resources_max.ngpus = 10
set queue iworkq resources_min.ngpus = 1
set queue iworkq resources_default.arch = linux
set queue iworkq resources_default.place = free
set queue iworkq default_chunk.mem = 512mb
set queue iworkq default_chunk.ncpus = 2
set queue iworkq enabled = True
set queue iworkq started = True2a. Configure at the Queue Level: Increase More GPU Chunk so that more users can use. Similarly, lower the CPU Chunk to spread our among the con-current session
Qmgr: set queue iworkq resources_max.ngpus = 20
Qmgr: set queue iworkq default_chunk.ncpus = 1
Qmgr: p q iworkq
2b. Configure at the Node Level: Increase the GPU Chunk at the node level to the number you use at the Queue Level. Make sure the number is the same.
Qmgr: p n hpc-r001
#
# Create nodes and set their properties.
#
#
# Create and define node VizSvr1
#
create node VizSvr1
set node VizSvr1 state = free
set node VizSvr1 resources_available.allows_container = False
set node VizSvr1 resources_available.arch = linux
set node VizSvr1 resources_available.host = VizSvr1
set node VizSvr1 resources_available.mem = 791887872kb
set node VizSvr1 resources_available.ncpus = 24
set node VizSvr1 resources_available.ngpus = 10
set node VizSvr1 resources_available.vnode = VizSvr1
set node VizSvr1 queue = iworkq
set node VizSvr1 resv_enable = TrueQmgr: set node hpc-r001 resources_available.ngpus = 20Qmgr: qCan verify by logging more session and testing it
[root@VizSvr1 ~]# qstat -ans | grep iworkq
94544.VizSvr1 user1 iworkq xterm 268906 1 1 256mb 720:0 R 409:5
116984.VizSvr1 user1 iworkq Abaqus 101260 1 1 256mb 720:0 R 76:38
118478.VizSvr1 user2 iworkq Ansys 236421 1 1 256mb 720:0 R 51:37
118487.VizSvr1 user3 iworkq Ansys 255657 1 1 256mb 720:0 R 49:51
119676.VizSvr1 user4 iworkq Ansys 308767 1 1 256mb 720:0 R 41:40
119862.VizSvr1 user5 iworkq Matlab 429798 1 1 256mb 720:0 R 23:54
120949.VizSvr1 user6 iworkq Ansys 450449 1 1 256mb 720:0 R 21:12
121229.VizSvr1 user7 iworkq xterm 85917 1 1 256mb 720:0 R 03:54
121646.VizSvr1 user8 iworkq xterm 101901 1 1 256mb 720:0 R 01:57
121664.VizSvr1 user9 iworkq xterm 111567 1 1 256mb 720:0 R 00:01
121666.VizSvr1 user9 iworkq xterm 112374 1 1 256mb 720:0 R 00:00