
IBM Spectrum Scale Container Native Storage Access (CNSA) allows the deployment of Spectrum Scale in a Red Hat OpenShift cluster. Using a remote mount attached file system, CNSA provides a persistent data store to be accessed by the applications via the IBM Spectrum Scale Container Storage Interface (CSI) driver using Persistent Volumes (PVs).
Xe-HPC and Ponte Vecchio
Intel started a brand new architecture, built for scalability and designed to take advantage of the most advanced silicon technologies: Xe HPC. With incredible hardware like Ponte Vecchio and an open, standards-based software stack in oneAPI, Intel is already seeing leadership performance in AI workloads like ResNet-50.
What is Data Fabric?
A data fabric is an architectural pattern that dynamically orchestrates disparate sources across a hybrid and multicloud landscape to provide business-ready data that supports applications, analytics and business process automation.
What is NLP (Natural Language Processing)?
0:00 – Intro
0:38 – Unstructured data
1:12 – Structured data
2:03 – Natural Language Understanding (NLU) & Natural Language Generation (NLG)
2:36 – Machine Translation use case
3:40 – Virtual Assistance / Chat Bots use case
4:14 – Sentiment Analysis use case
4:44 – Spam Detection use case
5:44 – Tokenization
6:18 – Stemming & Lemmatization
7:42 – Part of Speech Tagging
8:22 – Named Entity Recognition (NER)
9:08 – Summary
voro++.hh: No such file or directory during compilation of lammps with voronoi
If you encounter an error such as the one below during compilation for lammps such as written in Compiling LAMMPS-15Jun20 with GNU 6 and OpenMPI 3
../compute_voronoi_atom.h:24:21: fatal error: voro++.hh: No such file or directoryThis is due to one of the a header file not found at /usr/local/lammps-29Oct20/src/compute_voronoi_atom.cpp. To resolve the issue, do take a look at Line 23 or 24 and edit to the path where you place voro++.hh
/* #include <voro++.hh> */
#include "/usr/local/lammps-29Oct20/lib/voronoi/voro++-0.4.6/src/voro++.hh"
References:
Intel Add AI/ML Improvements to Sapphire Rapids with AMX
The full article is taken from With AMX, Intel Adds AI/ML Sparkle to Sapphire Rapids
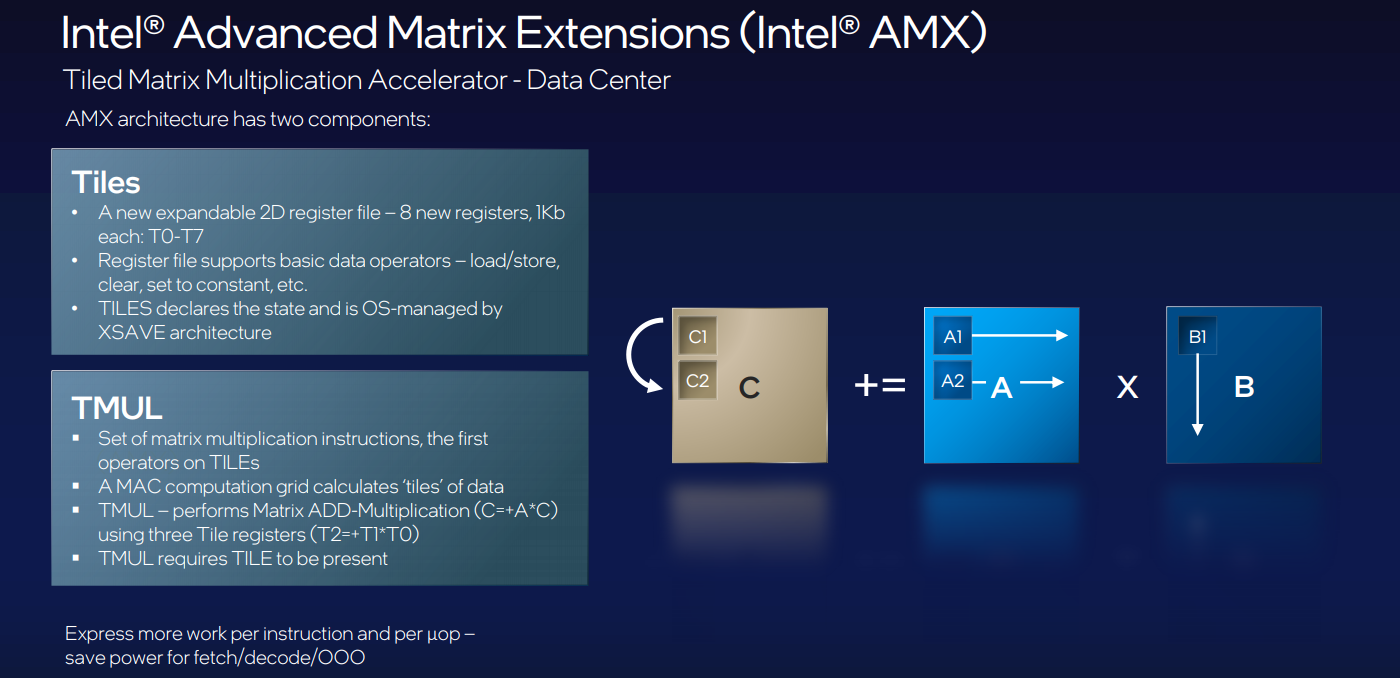
The best way for now to think of AMX is that it’s a matrix math overlay for the AVX-512 vector math units, as shown below. We can think of it like a “TensorCore” type unit for the CPU. The details about what this is were only a short snippet of the overall event, but it at least gives us an idea of how much space Intel is granting to training and inference specifically.
From The Next Platform “With AMX, Intel Adds AI/ML Sparkle to Sapphire Rapids”
Data comes directly into the tiles while at the same time, the host hops ahead and dispatches the loads for the toles. TMUL operates on data the moment it’s ready. At the end of each multiplication round, the tiles move to cache and SIMD post-processing and storing. The goal on the software side is to make sure both the host and AMX unit are running simultaneously.
The prioritization for AMX toward real-world AI workloads also meant a reckoning for how users were considering training versus inference. While the latency and programmability benefits of having training stay local are critical, and could well be a selling point for scalable training workloads on the CPU, inference has been the sweet spot for Intel thus far and AMX caters to that realization.
The 9th Annual MVAPICH User Group (MUG) conference

The 9th Annual MVAPICH User Group (MUG) conference will be held virtually with free registration from August 23-25, 2021. An exciting program has been put together with the following highlights:
- Two Keynote Talks by Luiz DeRose from Oracle and Gilad Shainer from NVIDIA
- Seven Tutorials/Demos (AWS, NVIDIA, Oracle, Rockport Networks, X-ScaleSolutions, and The Ohio State University)
- 16 Invited Talks from many organizations (LLNL, INL, Broadcom, Rockport Networks, Microsoft Azure, AWS, Paratools and University of Oregon, CWRU, SDSC, TACC, KISTI, Konkuk University, UTK, Redhat, NSF, X-ScaleSolutions, and OSC)
- 12 Short Presentations from the MVAPICH2 project members
- A talk on the Future Roadmap of the MVAPICH2 Project
- A special session on the newly funded NSF AI Institute – ICICLE (https://icicle.osu.edu/)
The detailed program is available from http://mug.mvapich.cse.ohio-state.edu/program/
All interested parties are welcome to attend the event free. The registration link is available from the following link: http://mug.mvapich.cse.ohio-state.edu/registration/
Session Trunking for NFS available in RHEL-8
This Article is taken from Is NFS session trunking available in RHEL?
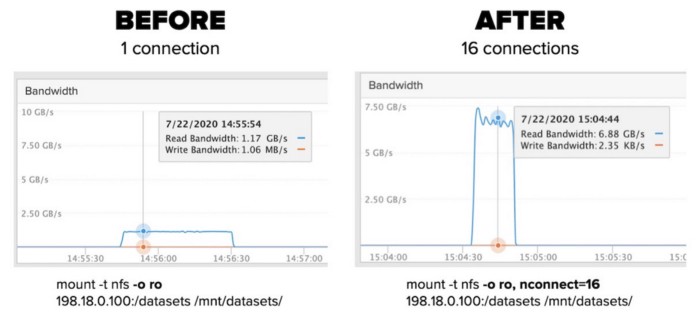
Session trunking, whereby one can have multiple TCP connections to the same NFS server with the same IP address is provided by nconnect. This feature is available in RHEL 8
RHSA-2020:4431 for the package(s) kernel-4.18.0-240.el8 or later.
RHBA-2020:4530 for the package(s) nfs-utils-2.3.3-35.el8 libnfsidmap-2.3.3-35.el8 or later.
You can configure on the client side up to 16 connection
[root@nfs-client ~]# mount -t nfs 192.168.0.2:/nfs-share /nfs-share -o nosharecache,nconnect=16You can see by using the command
[root@nfs-client ~]# cat /proc/self/mountstats
......
......
RPC iostats version: 1.1 p/v: 100003/4 (nfs)
xprt: tcp 991 0 2 0 39 13 13 0 13 0 2 0 0
xprt: tcp 798 0 2 0 39 6 6 0 6 0 2 0 0
xprt: tcp 768 0 2 0 39 6 6 0 6 0 2 0 0
xprt: tcp 1013 0 2 0 39 4 4 0 4 0 2 0 0
xprt: tcp 828 0 2 0 39 4 4 0 4 0 2 0 0
xprt: tcp 702 0 2 0 39 2 2 0 2 0 2 0 0
xprt: tcp 783 0 2 0 39 2 2 0 2 0 2 0 0
xprt: tcp 858 0 2 0 39 2 2 0 2 0 2 0 0
.....Someone recorded multiple performance increase when used on Pure Storage acting as a NFS Server. at Use nconnect to effortlessly increase NFS performance
References:
Pawsey Supercomputing Centre deploy 130 PB of Multi-Tier Storage with Ceph

Article is taken from HPCWire “Pawsey Supercomputing Centre to Deploy 130PB of Multi-Tier Storage“
The system has been designed to be both cost-effective and scalable.
HPCWire “Pawsey Supercomputing Centre to Deploy 130PB of Multi-Tier Storage”
To maximise value, Pawsey has invested in Ceph, software for building storage systems out of generic hardware, and has built the online storage infrastructure around Ceph in-house. As more servers are added, the online object storage becomes more stable, resilient, and even faster.
“That’s how we were able to build a 60 PB system on this budget,” explains Gray.
“An important part of this long-term storage upgrade was to demonstrate how it can be done in a financially scalable way. In a world of mega-science projects like the Square Kilometre Array, we need to develop more cost-effective ways of providing massive storage.”
The Data Centre is the New Unit of Computing
A revisit on Nvidia GTC 2021. A worthwhile thought to think through.
NVIDIA BlueField-3 DPU, the most powerful software-defined, hardware-accelerated data center on a chip. The #datacenter is the new unit of computing and the BlueField-2 DPU is now available to offload and accelerate the networking, storage, and security tasks within overtaxed data centers.
