
Nvidia and IBM did a complex proof-of-concept to demonstrate the scaling of AI workload using Nvidia DGX, Red Hat OpenShift and IBM Spectrum Scale at the example of ResNet-50 and the segmentation of images using the Audi A2D2 dataset. The project team published an IBM Redpaper with all the technical details and will present the key learnings and results.
File System
WekaIO Beats Big Systems on the IO-500 10 Node Challenge
What is IO-500 Node Challenge?
The IO-500 10 Node Challenge is a ranked list comparing storage systems that work in tandem with the world’s largest supercomputers. By limiting the benchmark to 10 nodes, the test challenges single client performance from the storage system. Each system is evaluated using the IO-500 benchmark that measures the storage performance using read/write bandwidth for large files and read/write/listing performance for small files…. from InsideHPC
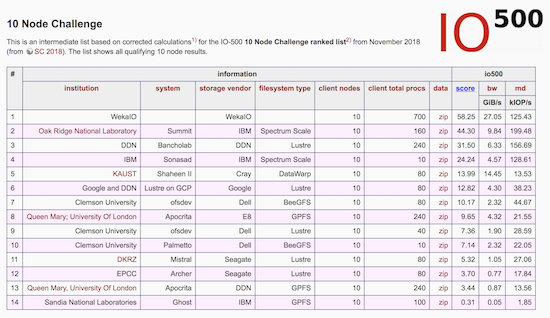
For more information, do look at WekaIO Beats Big Systems on the IO-500 10 Node Challenge
Spectrum Scale Solutions
- NVMe storage via RDMA storage via E8, Excelero
Lowest-Latency Distributed Block Storage for IBM Spectrum Scale
Excelero NVMesh, Lowest-Latency Distributed Block Storage for IBM Spectrum Scale - Community server + Spectrum Scale Erasure coding
IBM Spectrum LSF and IBM Spectrum Scale User Group Erasure Code Edition - IBM ESS NVMe edition (going to be released in this Q4)
https://www.ibm.com/downloads/cas/MNEQGQVP
https://www.spectrumscaleug.org/wp-content/uploads/2019/05/SSSD19DE-Day-1-03-IBM-Spectrum-Storage-for-AI-with-Nvidia-DGX.pdf - Existing IBM ESS
Accelerate with IBM Storage: Building and Deploying Elastic Storage Server (ESS)
Spectrum Scale User Group, SCA19 Singapore (March)
Taken from https://www.spectrumscaleug.org/presentations/
- SCA19 – 01 – Spectrum Scale Use Cases (Ulf Troppens, IBM)
- SCA19 – 02 – Optimize your data pipeline for analytics and AI (Par Hettinga, IBM)
- SCA19 – 03 – Data Management for autonomous driving development (Frank Kraemer, IBM)
- SCA19 – 04 – What is new in Spectrum Scale (Wei Gong, IBM)
- SCA19 – 05 – What is new in ESS (Chris Maestas, IBM)
- SCA19 – 06 – What is new in Support (Ravikumar Ramaswamy, IBM)
- SCA19 – 07 – Spectrum Scale on AWS Marketplace (Smita Raut, IBM)
- SCA19 – 09 – Genomics Deployments Enabling Precision Medicine with IBM Spectrum Scale (Sandeep Patil, IBM)
- SCA19 – 10 – Running Spark Hadoop workload on Spectrum Scale (Wei Gong, IBM)
- SCA19 – 11 – Lenovo – HPC Storage Solutions Update (Michael Hennecke, Lenovo)
- SCA19 – 12 – Spectrum Scale and containers (Smita Raut, IBM)
- SCA19 – 13- Tiering cold data to IBM Spectrum Archive (Khanh Ngo, IBM)
- EuXFEL–online & offline data processing and storage (Martin Gasthuber, Stefan Dietrich, Janusz Malka – DESY/IT Kryzsztof Wrona, Janusz Szuba – EuXFEL CHEP16 – San Francisco)
Technical Blogs on IBM Spectrum Scale v5.0.2.0
- How NFS exports became more dynamic with Spectrum Scale 5.0.2
https://developer.ibm.com/storage/2018/10/02/nfs-exports-became-dynamic-spectrum-scale-5-0-2/ - HPC storage on AWS (IBM Spectrum Scale)
https://developer.ibm.com/storage/2018/10/02/hpc-storage-aws-ibm-spectrum-scale/ - Upgrade with Excluding the node(s) using Install-toolkit
https://developer.ibm.com/storage/2018/09/30/upgrade-excluding-nodes-using-install-toolkit/ - Offline upgrade using Install-toolkit
https://developer.ibm.com/storage/2018/09/30/offline-upgrade-using-install-toolkit/ - IBM Spectrum Scale for Linux on IBM Z ? What’s new in IBM Spectrum Scale 5.0.2
https://developer.ibm.com/storage/2018/09/21/ibm-spectrum-scale-for-linux-on-ibm-z-whats-new-in-ibm-spectrum-scale-5-0-2/ - What’s New in IBM Spectrum Scale 5.0.2
https://developer.ibm.com/storage/2018/09/15/whats-new-ibm-spectrum-scale-5-0-2/ - Starting IBM Spectrum Scale 5.0.2 release, the installation toolkit supports upgrade rerun if fresh upgrade fails.
https://developer.ibm.com/storage/2018/09/15/starting-ibm-spectrum-scale-5-0-2-release-installation-toolkit-supports-upgrade-rerun-fresh-upgrade-fails/ - IBM Spectrum Scale installation toolkit enhancements over releases 5.0.2.0
https://developer.ibm.com/storage/2018/09/15/ibm-spectrum-scale-installation-toolkit-enhancements-releases-5-0-2-0/ - Announcing HDP 3.0 support with IBM Spectrum Scale
https://developer.ibm.com/storage/2018/08/31/announcing-hdp-3-0-support-ibm-spectrum-scale/ - IBM Spectrum Scale Tuning Overview for Hadoop Workload
https://developer.ibm.com/storage/2018/08/20/ibm-spectrum-scale-tuning-overview-hadoop-workload/ - Making the Most of Multicloud Storage
https://developer.ibm.com/storage/2018/08/13/making-multicloud-storage/ - Disaster Recovery for Transparent Cloud Tiering using SOBAR
https://developer.ibm.com/storage/2018/08/13/disaster-recovery-transparent-cloud-tiering-using-sobar/ - Your Optimal Choice of AI Storage for Today and Tomorrow
https://developer.ibm.com/storage/2018/08/10/spectrum-scale-ai-workloads/ - Analyze IBM Spectrum Scale File Access Audit with ELK Stack
https://developer.ibm.com/storage/2018/07/30/analyze-ibm-spectrum-scale-file-access-audit-elk-stack/ - Mellanox SX1710 40G switch MLAG configuration for IBM ESS
https://developer.ibm.com/storage/2018/07/12/mellanox-sx1710-40g-switcher-mlag-configuration/ - Protocol Problem Determination Guide for IBM Spectrum Scale SMB and NFS Access issues
https://developer.ibm.com/storage/2018/07/10/protocol-problem-determination-guide-ibm-spectrum-scale-smb-nfs-access-issues/ - Access Control in IBM Spectrum Scale Object
https://developer.ibm.com/storage/2018/07/06/access-control-ibm-spectrum-scale-object/ - IBM Spectrum Scale HDFS Transparency Docker support
https://developer.ibm.com/storage/2018/07/06/ibm-spectrum-scale-hdfs-transparency-docker-support/ - Protocol Problem Determination Guide for IBM Spectrum Scale Log Collection
https://developer.ibm.com/storage/2018/07/04/protocol-problem-determination-guide-ibm-spectrum-scale-log-collection/
Checking Faulty Disks on GPFS Native RAID pdisks.
mmlspdisk which Lists information for one or more GPFS Native RAID pdisks. To check faulty disks, do the commands
# mmlspdisk all --not-ok mmlspdisk: [I] No disks were found.
OR
# mmlspdisk all --replace mmlspdisk: [I] No disks were found.
Faulty disks accepting I/O request and not returning any failure for GPFS
We have encountered a situation where a defunct disk was accepting IO request and did not return any failure in time. As a result, these IO requests hanged there till time out (default 10 seconds). Typically, Spectrum Scale/GPFS will fail to read or write a disk, the failure is written in log and we have to shift IO to other available disks which should be quick.
Normally such operations should return in 20 milliseconds or less. When we have IO timeout, this request has wasted us
10 seconds / 20 milliseconds = 500 times of time. Even if Spectrum Scale/GPFS is able to choose a fast disk in the second attempt, we are much slower than normal.
Due to the utilization of striping technology, a bad/slow disks always affects IO of many files, much more than the situation without striping. IO on the same file involves more than several disks, and the IO has to wait for the slowest request to return. So a bad/slow disk may have considerable influence on Spectrum Scale/GPFS performance.
Pre-check before restarting the NSD Nodes
Before restarting the NSD Nodes or Quorum Manager Nodes or other critical nodes, do check the following first to ensure the file system is in the right order before restarting.
1. Make sure all three quorum nodes are active.
# mmgetstate -N quorumnodes
*If any machine is not active, do *not* proceed
2. Make sure file system is mounted on machines
# mmlsmount gpfs0
If the file system is not mounted somewhere, we should try to resolve it first.
Spectrum Scale User Group @ London (April)
There was a good and varied topics being discussed at the Spectrum Scale
- Opening & welcome – Simon Thompson, Claire O’Toole, Ted Hoover
- Update Scale (video)/ ESS / Support (video) – Mathias Dietz & Chris Maestas
- MultiCloud Transparent Cloud Tiering (video) – Rob Basham
- Shared NVMe for High Performance Spectrum Scale Clusters (video)- Stuart Campbell
- User Talk – EBI MMAP issues (video – both speakers) – Jordi Valls / Sven Oehme
- GxFS Storage Appliance at Karlsruher Institute of Technology (video) – Jan Erik Sundermann
- Tooling Scale – Automation
- R&S VSA (Virtual storage access) Reliable fault tolerant storage in Broadcast (video) – Oliver Gappa
- Novel TCT: A brief demo on using TCT with alternative cloud gateways – Laurence Horrocks-Barlow
- Ten commandments of good I/O – Rosemary Francis
- Scientific Computing & Storage at The Francis Crick Institute – Michael Holliday
- Mixing storage systems in Spectrum Scale – Migrations & pools stories – Luis Bolinches
- File System Audit Logging / Running Spectrum Scale in a Vagrant environment – Chris Maestas
- AFM Deep Dive – Tuning and debugging – Venkateswara Puvvada
- User Talk – QMUL – Peter Childs
- Sponsor Talk – Lenovo – Michael Hennecke
- User Talk – MAX IV – Andreas Mattsson
- Sponsor Talk – DDN – Vic Cornell
- Cognititive, ML, Hortonworks – Yong ZY Zheng
Basic Tuning of RDMA Parameters for Spectrum Scale
If your cluster has symptoms of overload and GPFS kept reporting “overloaded” in GPFS logs like the ones below, you might get long waiters and sometimes deadlocks.
Wed Apr 11 15:53:44.232 2018: [I] Sending 'overloaded' status to the entire cluster Wed Apr 11 15:55:24.488 2018: [I] Sending 'overloaded' status to the entire cluster Wed Apr 11 15:57:04.743 2018: [I] Sending 'overloaded' status to the entire cluster Wed Apr 11 15:58:44.998 2018: [I] Sending 'overloaded' status to the entire cluster Wed Apr 11 16:00:25.253 2018: [I] Sending 'overloaded' status to the entire cluster Wed Apr 11 16:28:45.601 2018: [I] Sending 'overloaded' status to the entire cluster Wed Apr 11 16:33:56.817 2018: [N] sdrServ: Received deadlock notification from
Increase scatterBuffersize to a Number that match IB Fabric
One of the first tuning will be to tune the scatterBufferSize. According to the wiki, FDR10 can be tuned to 131072 and FDR14 can be tuned to 262144
The default value of 32768 may perform OK. If the CPU utilization on the NSD IO servers is observed to be high and client IO performance is lower than expected, increasing the value of scatterBufferSize on the clients may improve performance.
# mmchconfig scatterBufferSize=131072
There are other parameters which can be tuned. But the scatterBufferSize worked immediately for me.
verbsRdmaSend
verbsRdmasPerConnection
verbsRdmasPerNode
Disable verbsRdmaSend=no
# mmchconfig verbsRdmaSend=no -N nsd1,nsd2
Verify settings has taken place
# mmfsadm dump config | grep verbsRdmasPerNode
Increase verbsRdmasPerNode to 514 for NSD Nodes
# mmchonfig verbsRdmasPerNode=514 -N nsd1,nsd2
References:
