This one-day, LIVE virtual conference features talks, panels, and a hands-on learning experience focused on using oneAPI, DPC++, and AI/ML to accelerate performance of cross-architecture workloads (CPU, GPU, FPGA, and other accelerators).
Register now to:
Connect with fellow developers and innovators.
Learn about the latest developer tools for oneAPI.
Hear from thought leaders in industry and academia who are working on innovative cross-platform, multi-vendor oneAPI solutions.
Discover real world projects using oneAPI to accelerate data science and AI pipelines.
Dive into a hands-on session on Intel® oneAPI toolkits for HPC and AI applications.
Join a vibrant community supporting each other using oneAPI, DPC++ and AI.
Intel started a brand new architecture, built for scalability and designed to take advantage of the most advanced silicon technologies: Xe HPC. With incredible hardware like Ponte Vecchio and an open, standards-based software stack in oneAPI, Intel is already seeing leadership performance in AI workloads like ResNet-50.
Picture taken from With AMX, Intel Adds AI/ML Sparkle to Sapphire Rapids
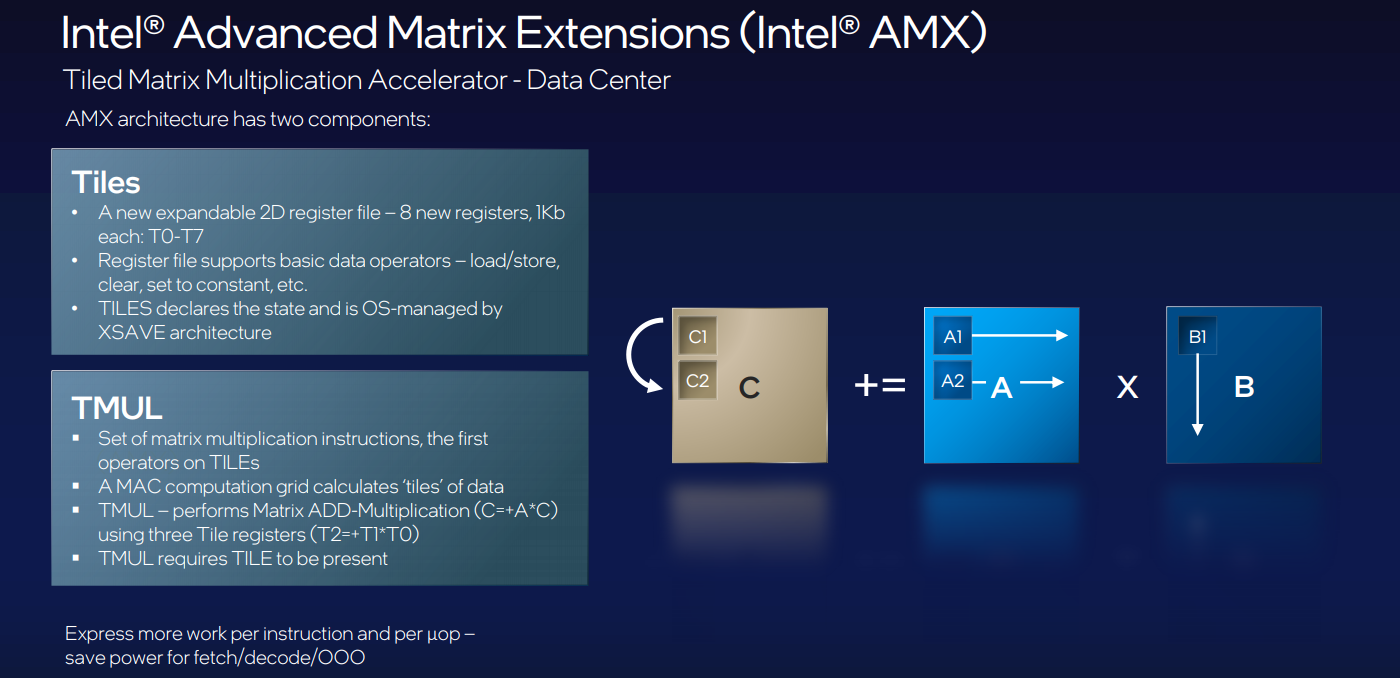
The best way for now to think of AMX is that it’s a matrix math overlay for the AVX-512 vector math units, as shown below. We can think of it like a “TensorCore” type unit for the CPU. The details about what this is were only a short snippet of the overall event, but it at least gives us an idea of how much space Intel is granting to training and inference specifically.
Data comes directly into the tiles while at the same time, the host hops ahead and dispatches the loads for the toles. TMUL operates on data the moment it’s ready. At the end of each multiplication round, the tiles move to cache and SIMD post-processing and storing. The goal on the software side is to make sure both the host and AMX unit are running simultaneously.
The prioritization for AMX toward real-world AI workloads also meant a reckoning for how users were considering training versus inference. While the latency and programmability benefits of having training stay local are critical, and could well be a selling point for scalable training workloads on the CPU, inference has been the sweet spot for Intel thus far and AMX caters to that realization.
From The Next Platform “With AMX, Intel Adds AI/ML Sparkle to Sapphire Rapids”
High quality visualization is in high demand for all artists. Intel collaborates with Arnold for on-going optimizations, bringing the best CPU rendering to users.
During the “Intel Accelerated” webcast, Intel’s technology leaders revealed one of the most detailed process and packaging technology roadmaps the company has provided. The event on July 26, 2021, showcased a series of foundational innovations that will power products through 2025 and beyond. As part of the presentations, Intel announced RibbonFET, its first new transistor architecture in more than a decade, and PowerVia, an industry-first new backside power delivery method. (Credit: Intel Corporation)
Intel has delayed production of its next-generation Xeon Scalable CPUs, code-named Sapphire Rapids, to the first quarter of 2022 and said it will start ramping shipments by at least April of next year.
Spelman said Intel is delaying Sapphire Rapids, the 10-nanometer successor to the recently launched Ice Lake server processors, because of extra time needed to validate the CPU.
“Given the breadth of enhancements in Sapphire Rapids, we are incorporating additional validation time prior to the production release, which will streamline the deployment process for our customers and partners. Based on this, we now expect Sapphire Rapids to be in production in the first quarter of 2022, with ramp beginning in the second quarter of 2022,” Spelman wrote.
CRN (Intel Delays Sapphire Rapids Xeon CPU Production To Q1 2022)
CXL Fireside Chat Stephen Van Doren, Intel Fellow, Director of Processor Interconnect Architecture, Intel Corporation
Intel System Server D50TNP for HPC Scott Misage, Manager Product Development & Architecture, Intel Corporation Brian Caslis, Product Line Manager, Intel Corporation Jim Russell, Project Design Manager, Intel Corporation
If the data center is part of your development wheelhouse, you’re likely familiar with a little CPU called “Xeon”. This webinar unpacks the latest methodologies of tuning complex AI and HPC workloads for the third generation Xeon platform (formerly code-named Ice Lake).
Delivering up to 40 cores per processor, 3rd Gen Intel® Xeon® Scalable processors are designed for compute-intense, data-centric workloads spanning the cloud to the network and the edge.
In this session, Intel engineer Vladimir Tsymbal will show you how to optimize your AI and HPC applications and solutions to unlock the full spectrum of these processors’ power. You’ll learn:
The top-down tuning methodology that uses Xeon hardware-performance metrics to identify issues including critical bottlenecks caused by data locality, CPU interconnect bandwidth, cache limitations, instructions execution stalls, and I/O interfaces
How a high-level HPC Characterization Analysis helps you find inefficient parallel tasks
Libfabric is a low-level communication abstraction for high-performance networks. It hides most transport and hardware implementation details from middleware and applications to provide high-performance portability between diverse fabrics.
Using the Intel MPI Library Distribution of Libfabric
By default, mpivars.sh sets the environment to the version of libfabric shipped with the Intel MPI Library. To disable this, use the I_MPI_OFI_LIBRARY_INTERNAL environment variable or -ofi_internal (by default ofi_internal=1)
To select the OFI provider from the libfabric library, you can use definte the name of the OFI Provider to load
export I_MPI_OFI_PROVIDER=tcp
Logging Interfaces
FI_LOG_LEVEL=<level> controls the amount of logging data that is output. The following log levels are defined:
Warn: Warn is the least verbose setting and is intended for reporting errors or warnings.
Trace: Trace is more verbose and is meant to include non-detailed output helpful for tracing program execution.
Info: Info is high traffic and meant for detailed output.
Debug: Debug is high traffic and is likely to impact application performance. Debug output is only available if the library has been compiled with debugging enabled.