
The full article is taken from With AMX, Intel Adds AI/ML Sparkle to Sapphire Rapids
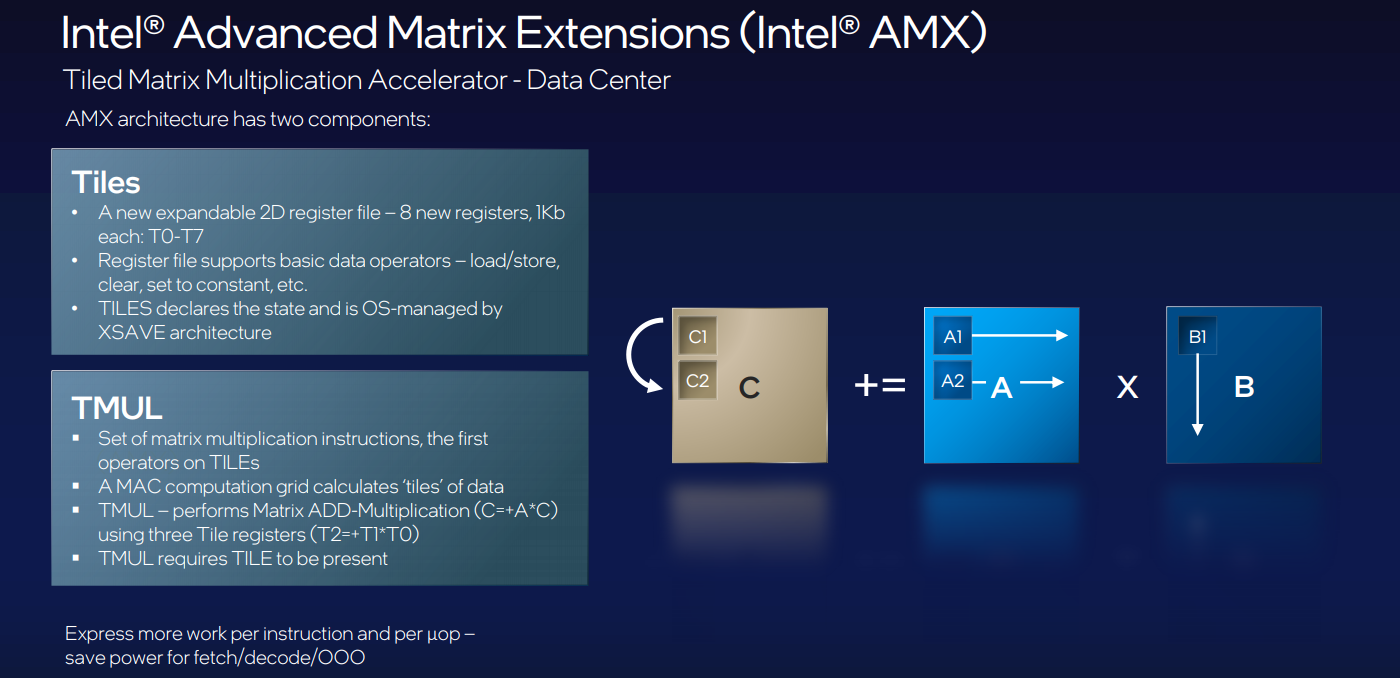
The best way for now to think of AMX is that it’s a matrix math overlay for the AVX-512 vector math units, as shown below. We can think of it like a “TensorCore” type unit for the CPU. The details about what this is were only a short snippet of the overall event, but it at least gives us an idea of how much space Intel is granting to training and inference specifically.
From The Next Platform “With AMX, Intel Adds AI/ML Sparkle to Sapphire Rapids”
Data comes directly into the tiles while at the same time, the host hops ahead and dispatches the loads for the toles. TMUL operates on data the moment it’s ready. At the end of each multiplication round, the tiles move to cache and SIMD post-processing and storing. The goal on the software side is to make sure both the host and AMX unit are running simultaneously.
The prioritization for AMX toward real-world AI workloads also meant a reckoning for how users were considering training versus inference. While the latency and programmability benefits of having training stay local are critical, and could well be a selling point for scalable training workloads on the CPU, inference has been the sweet spot for Intel thus far and AMX caters to that realization.
